Octavo Encuentro. Aprendiendo a Programar en 30 lecciones
Octavo encuentro
By Yanina Bellini Saibene in Español rstats Education 100DaysToOffload
May 1, 2024
En esta clase volvemos a trabajar con los conjuntos de datos y las preguntas que nos hicimos. Vamos a convertir algunos tipos de datos y trabajar con characteres para contestar dos preguntas y hacer un grafico.
Preguntas para (mas adelante) ahora.
En el quinto encuentro dejamos una serie de preguntas para mas adelante. Hoy vamos a seleccionar de ese listado y vamos a resolverlas
-
Copas: ordenar de mayor a menor o al revez la audiencia de los mundiales.
-
Jugadores:
- ordenar los jugadores por cantidad de goles.
- todos los jugadores que metieron 1 o mas goles en el segundo tiempo.
Ordenar las copas por audiencia.
El conjunto de datos copas tiene una columna llamada Attendance que contiene la cantidad de gente que fue a ver los partidos a los estadios.
La funcion para ordenar es arrange y si la usamos este es el resultado que obtenemos:
copas %>%
arrange(Attendance)
# A tibble: 20 × 10
Year Country Winner `Runners-Up` Third Fourth GoalsScored QualifiedTeams MatchesPlayed Attendance
<date> <chr> <chr> <chr> <chr> <chr> <int> <int> <int> <chr>
1 1950-01-01 Brazil Uruguay Brazil Sweden Spain 88 13 22 1.045.246
2 1978-01-01 Argentina Argentina Netherlands Brazil Italy 102 16 38 1.545.791
3 1966-01-01 England England Germany FR Portug… Sovie… 89 16 32 1.563.135
4 1970-01-01 Mexico Brazil Italy German… Urugu… 95 16 32 1.603.975
5 1974-01-01 Germany Germany FR Netherlands Poland Brazil 97 16 38 1.865.753
6 1982-01-01 Spain Italy Germany FR Poland France 146 24 52 2.109.723
7 1986-01-01 Mexico Argentina Germany FR France Belgi… 132 24 52 2.394.031
8 1990-01-01 Italy Germany FR Argentina Italy Engla… 115 24 52 2.516.215
9 2002-01-01 Korea/Japan Brazil Germany Turkey Korea… 161 32 64 2.705.197
10 1998-01-01 France France Brazil Croatia Nethe… 171 32 64 2.785.100
11 2010-01-01 South Africa Spain Netherlands Germany Urugu… 145 32 64 3.178.856
12 2006-01-01 Germany Italy France Germany Portu… 147 32 64 3.359.439
13 2014-01-01 Brazil Germany Argentina Nether… Brazil 171 32 64 3.386.810
14 1994-01-01 USA Brazil Italy Sweden Bulga… 141 24 52 3.587.538
15 1934-01-01 Italy Italy Czechoslovakia Germany Austr… 70 16 17 363.000
16 1938-01-01 France Italy Hungary Brazil Sweden 84 15 18 375.700
17 1930-01-01 Uruguay Uruguay Argentina USA Yugos… 70 13 18 590.549
18 1954-01-01 Switzerland Germany FR Hungary Austria Urugu… 140 16 26 768.607
19 1958-01-01 Sweden Brazil Sweden France Germa… 126 16 35 819.810
20 1962-01-01 Chile Brazil Czechoslovakia Chile Yugos… 89 16 32 893.172
>
Como podemos ver, el orden no es el esperado si la variable fuera numerica, ese orden corresponde a un orden alfabetico. Por lo que el problema esta en el tipo de dato que tiene esa columna. Al importar los datos leyendo el CSV lo hace como caracter. Cuando intentamos asignar el tipo correcto en la lectura de los datos no pudimos lograrlo:
- la columna se leia con todos valores nulos.
- la columna se leia con datos pero contenia valores erroneos.
Analicemos los datos de esa columna para determinar que esta pasando:
glimpse(copas)
Rows: 20
Columns: 10
$ Year <date> 1930-01-01, 1934-01-01, 1938-01-01, 1950-01-01, 1954-01-01, 1958-01-01, 1962-01-01, 1966-01-0…
$ Country <chr> "Uruguay", "Italy", "France", "Brazil", "Switzerland", "Sweden", "Chile", "England", "Mexico",…
$ Winner <chr> "Uruguay", "Italy", "Italy", "Uruguay", "Germany FR", "Brazil", "Brazil", "England", "Brazil",…
$ `Runners-Up` <chr> "Argentina", "Czechoslovakia", "Hungary", "Brazil", "Hungary", "Sweden", "Czechoslovakia", "Ge…
$ Third <chr> "USA", "Germany", "Brazil", "Sweden", "Austria", "France", "Chile", "Portugal", "Germany FR", …
$ Fourth <chr> "Yugoslavia", "Austria", "Sweden", "Spain", "Uruguay", "Germany FR", "Yugoslavia", "Soviet Uni…
$ GoalsScored <int> 70, 70, 84, 88, 140, 126, 89, 89, 95, 97, 102, 146, 132, 115, 141, 171, 161, 147, 145, 171
$ QualifiedTeams <int> 13, 16, 15, 13, 16, 16, 16, 16, 16, 16, 16, 24, 24, 24, 24, 32, 32, 32, 32, 32
$ MatchesPlayed <int> 18, 17, 18, 22, 26, 35, 32, 32, 32, 38, 38, 52, 52, 52, 52, 64, 64, 64, 64, 64
$ Attendance <chr> "590.549", "363.000", "375.700", "1.045.246", "768.607", "819.810", "893.172", "1.563.135", "1…
>
Los valores en Attendance son numeros que estan usando el punto como separador de miles. Y es por eso que son leidos como texto en vez de numeros.
El paquete readr tiene una funcion llamada parse_number que extrae los numeros. Esto elimina cualquier carácter no numérico antes o después del primer número. El separador de miles especificado por la configuración regional se ignora dentro del número. Veamos que hace esta funcion:
copas %>%
mutate(asistencia = parse_number(Attendance))
# A tibble: 20 × 11
Year Country Winner `Runners-Up` Third Fourth GoalsScored QualifiedTeams MatchesPlayed Attendance asistencia
<date> <chr> <chr> <chr> <chr> <chr> <int> <int> <int> <chr> <dbl>
1 1930-01-01 Uruguay Urugu… Argentina USA Yugos… 70 13 18 590.549 591.
2 1934-01-01 Italy Italy Czechoslova… Germ… Austr… 70 16 17 363.000 363
3 1938-01-01 France Italy Hungary Braz… Sweden 84 15 18 375.700 376.
4 1950-01-01 Brazil Urugu… Brazil Swed… Spain 88 13 22 1.045.246 1.04
5 1954-01-01 Switzerl… Germa… Hungary Aust… Urugu… 140 16 26 768.607 769.
6 1958-01-01 Sweden Brazil Sweden Fran… Germa… 126 16 35 819.810 820.
7 1962-01-01 Chile Brazil Czechoslova… Chile Yugos… 89 16 32 893.172 893.
8 1966-01-01 England Engla… Germany FR Port… Sovie… 89 16 32 1.563.135 1.56
9 1970-01-01 Mexico Brazil Italy Germ… Urugu… 95 16 32 1.603.975 1.60
10 1974-01-01 Germany Germa… Netherlands Pola… Brazil 97 16 38 1.865.753 1.86
11 1978-01-01 Argentina Argen… Netherlands Braz… Italy 102 16 38 1.545.791 1.54
12 1982-01-01 Spain Italy Germany FR Pola… France 146 24 52 2.109.723 2.11
13 1986-01-01 Mexico Argen… Germany FR Fran… Belgi… 132 24 52 2.394.031 2.39
14 1990-01-01 Italy Germa… Argentina Italy Engla… 115 24 52 2.516.215 2.52
15 1994-01-01 USA Brazil Italy Swed… Bulga… 141 24 52 3.587.538 3.59
16 1998-01-01 France France Brazil Croa… Nethe… 171 32 64 2.785.100 2.78
17 2002-01-01 Korea/Ja… Brazil Germany Turk… Korea… 161 32 64 2.705.197 2.70
18 2006-01-01 Germany Italy France Germ… Portu… 147 32 64 3.359.439 3.36
19 2010-01-01 South Af… Spain Netherlands Germ… Urugu… 145 32 64 3.178.856 3.18
20 2014-01-01 Brazil Germa… Argentina Neth… Brazil 171 32 64 3.386.810 3.39
Al utilizarla entiende el punto como un decimal y cambia el tipo de dato a doble. Esto no es correcto ya que los valores presentados corresponden a cientos de miles y a millones. Podemos indicarle a la funcion que el separador de miles es el punto y el de decimales es la coma. Para eso usamos la funcion readr::parse_number y le pasamos los argumentos locale = locale(grouping_mark = ".", decimal_mark = ","):
copas %>%
mutate(asistencia = parse_number(Attendance, locale = locale(grouping_mark = "."))) %>%
select(Attendance, asistencia)
# A tibble: 20 × 2
Attendance asistencia
<chr> <dbl>
1 590.549 590549
2 363.000 363000
3 375.700 375700
4 1.045.246 1045246
5 768.607 768607
6 819.810 819810
7 893.172 893172
8 1.563.135 1563135
9 1.603.975 1603975
10 1.865.753 1865753
11 1.545.791 1545791
12 2.109.723 2109723
13 2.394.031 2394031
14 2.516.215 2516215
15 3.587.538 3587538
16 2.785.100 2785100
17 2.705.197 2705197
18 3.359.439 3359439
19 3.178.856 3178856
20 3.386.810 3386810
>
Ahora si, los datos estan en el formato correcto y podemos ordenarlos usando arrange.
copas %>%
mutate(asistencia = parse_number(Attendance, locale = locale(grouping_mark = "."))) %>%
arrange(desc(asistencia)) %>%
select(Year, Country, Attendance, asistencia)
# A tibble: 20 × 4
Year Country Attendance asistencia
<date> <chr> <chr> <dbl>
1 1994-01-01 USA 3.587.538 3587538
2 2014-01-01 Brazil 3.386.810 3386810
3 2006-01-01 Germany 3.359.439 3359439
4 2010-01-01 South Africa 3.178.856 3178856
5 1998-01-01 France 2.785.100 2785100
6 2002-01-01 Korea/Japan 2.705.197 2705197
7 1990-01-01 Italy 2.516.215 2516215
8 1986-01-01 Mexico 2.394.031 2394031
9 1982-01-01 Spain 2.109.723 2109723
10 1974-01-01 Germany 1.865.753 1865753
11 1970-01-01 Mexico 1.603.975 1603975
12 1966-01-01 England 1.563.135 1563135
13 1978-01-01 Argentina 1.545.791 1545791
14 1950-01-01 Brazil 1.045.246 1045246
15 1962-01-01 Chile 893.172 893172
16 1958-01-01 Sweden 819.810 819810
17 1954-01-01 Switzerland 768.607 768607
18 1930-01-01 Uruguay 590.549 590549
19 1938-01-01 France 375.700 375700
20 1934-01-01 Italy 363.000 363000
>
Otra forma de solucionar el mismo problema es remover los puntos y luego transformalo en numero con las funciones
str_remove_all, que remueve los caracteres indicados en todas las ocurrencias que aparecen yas.numeric, que transforma al tipo numerico. Esta solucion aparece como una respuesta en StackOverflow y por eso la revisamos.
copas <- copas %>%
mutate(asistencia = as.numeric(str_remove_all(Attendance, fixed("."))))
Goleadores.
Para estas preguntas vamos a usar el conjunto de datos de jugadores. Hay una columna llamada Event con anotaciones al estilo “G20” o “Y56” que significan: “Gol a los 20 minutos” y “Tarjeta amarilla a los 56 minutos”, respectivamente. La columna puede tener ninguno (NA), uno o mas eventos por jugador. En el caso que tenga mas de un evento se separan con un espacio, como se muestra en la fila siete de la siguiente figura.
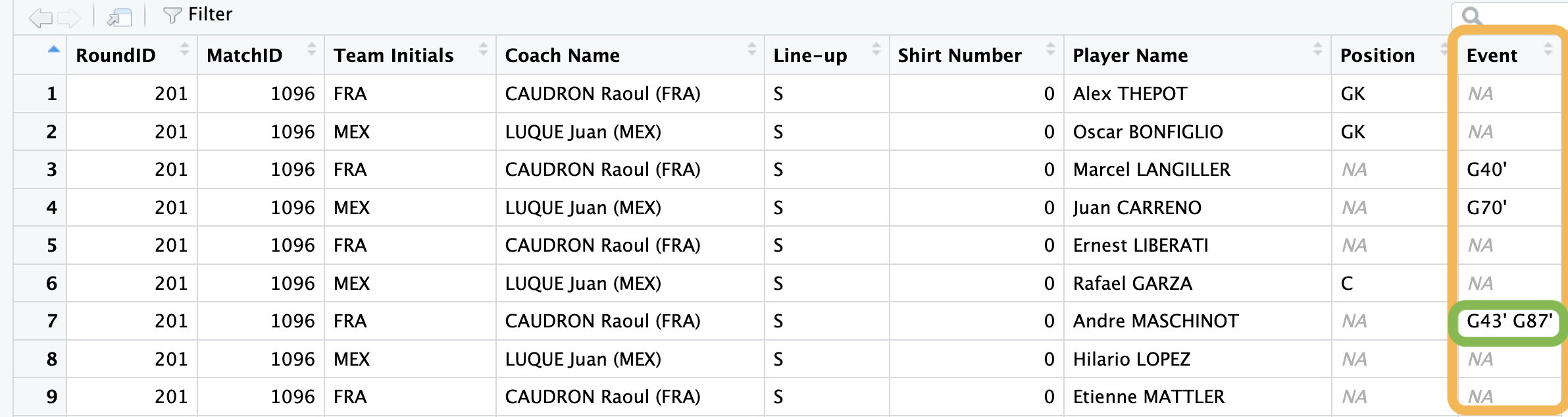
Para poder ordenar los jugadores por la cantidad de goles y saber quienes metieron goles en el segundo tiempo vamos a tener que poder contar los eventos “goles”. Para ello podemos separar los eventos en columnas diferentes o separarlos en filas diferentes.
Para este tipo de problema nos conviene separar los eventos en filas diferentes. Para eso vamos a usar la funcion separate_longer_delim del paquete tidyr. Esta funcion tiene como parametros la columna que queremos separar y el delimitador que vamos a usar. En este caso el delimitador es un espacio.
goleadores <- jugadores %>%
separate_longer_delim(Event, delim = " ")
Con este codigo obtenemos un conjunto de datos con una fila por cada evento y lo guardamos en el objeto goleadores, ahora la fila 7 se transformo en las filas 7 y 8 (dos filas), una con cada gol que hizo Andre Maschinot. Si chequeamos el conjunto de datos de jugadores tenia 37784 filas y ahora goleadores tiene xx filas.
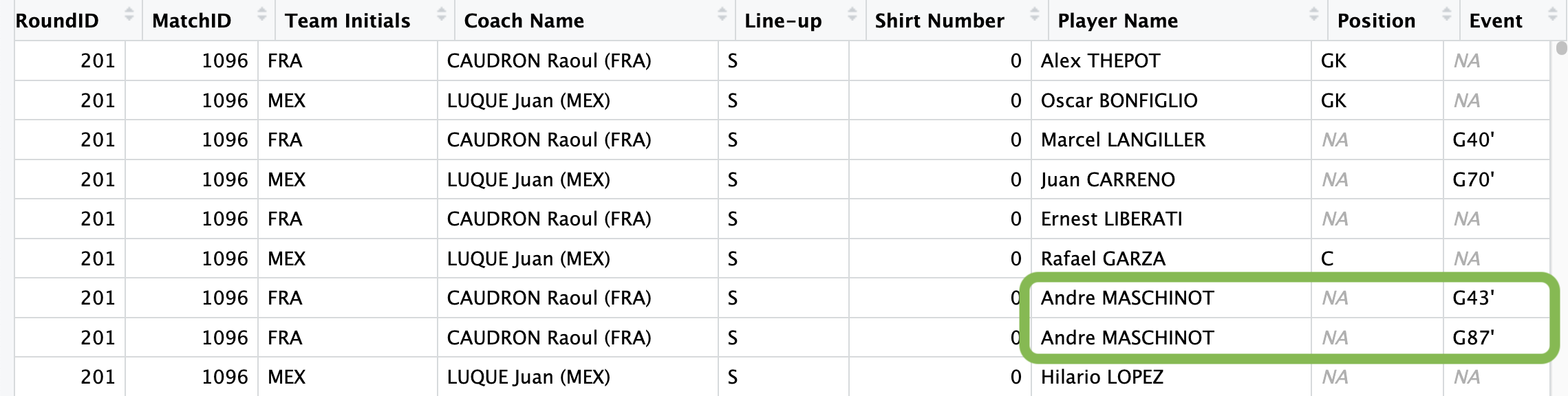
Ordenar los jugadores por cantidad de goles
El conjunto de datos de goles, ahora tiene una fila para cada evento relacionado a un jugador. Entre esos eventos estan los goles, pero no son los unicos. Asi que primero tenemos que quedarnos solo con los goles. Para eso vamos a usar la funcion filter de dplyr y la funcion str_detect de stringr que nos permite buscar patrones en un texto.
goleadores %>%
filter(str_detect(Event,"G"))
Para ordenar los jugadores por cantidad de goles vamos a tener que contar cuantas veces aparece cada jugador en la columna Player Name. La primera solucion que Juan Cruz propuso fue usar group_by y summarise para contar cuantas veces aparece cada jugador y por ende cuantos goles hizo. Luego usamos arrange y desc para ordenar de mayor a menor.
goleadores %>%
filter(str_detect(Event,"G")) %>%
group_by(`Player Name`) %>%
summarise(goles = n()) %>%
arrange(desc(n))
# A tibble: 1,187 × 2
`Player Name` n
<chr> <int>
1 KLOSE 17
2 RONALDO 16
3 Gerd MUELLER 13
4 Just FONTAINE 13
5 PEL� (Edson Arantes do Nascimento) 12
6 M�LLER 11
7 Sandor KOCSIS 11
8 Grzegorz LATO 10
9 Helmut RAHN 10
10 JAIRZINHO 9
# ℹ 1,177 more rows
# ℹ Use `print(n = ...)` to see more rows
Vemos en el resultado problemas de encoding que intentaremos resolver en las proximas clases.
Charlamos de otra manera de realizar la misma consulta y la segunda solucion que propuso fue usar count que es una forma mas simple de hacer lo mismo.
goleadores %>%
filter(str_detect(Event,"G")) %>%
count(`Player Name`) %>%
arrange(desc(n))
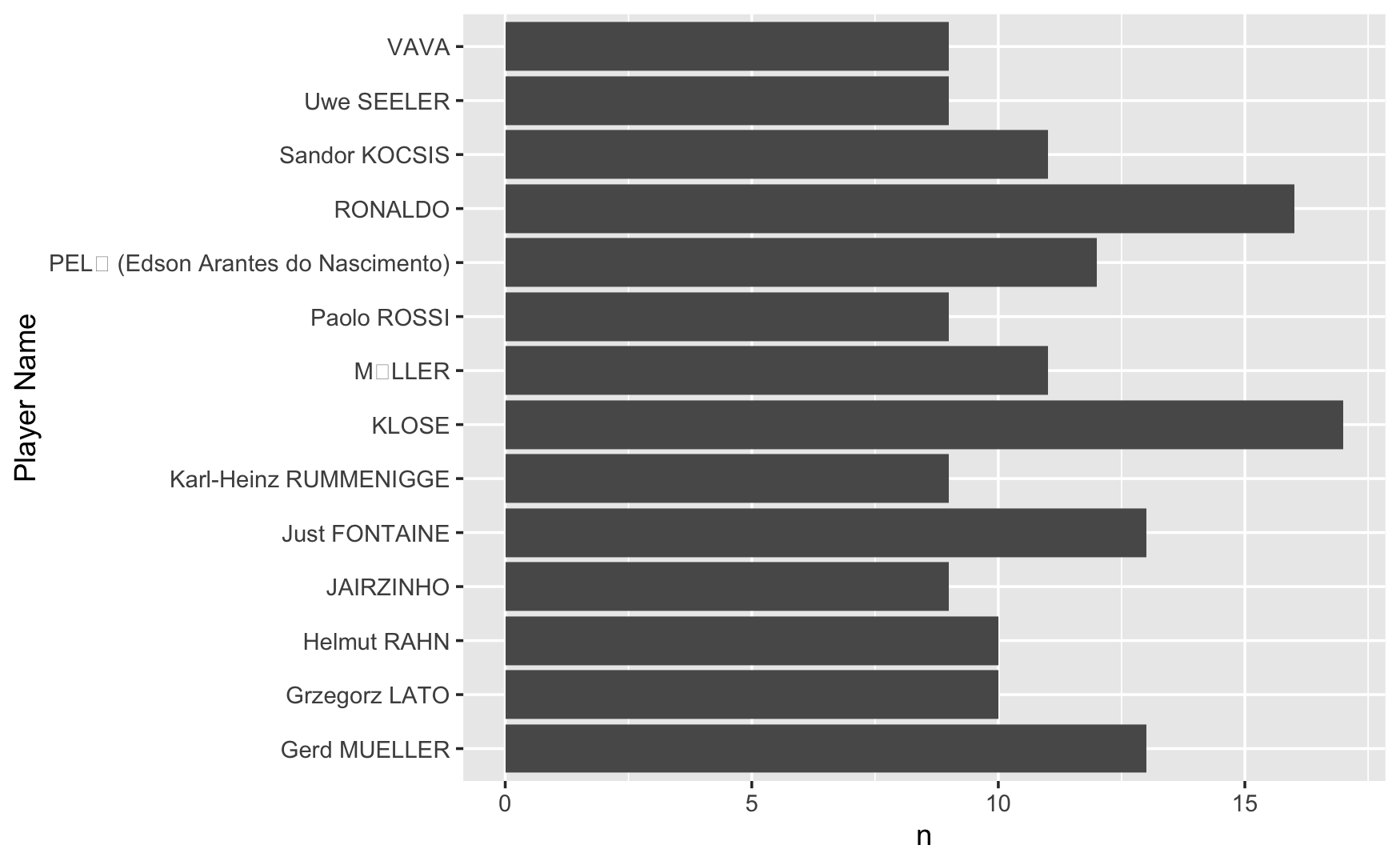
Ejercicio 1: Sacar los 10 jugadores mas importantes y realizar un grafico de barras.
Usando los resultados de los goleadores, seleccionar los 10 jugadores que mas goles hicieron y hacer un grafico de barras.
Para resolver este ejercicio introducimos la funcion top_n que nos permite seleccionar los n elementos mas grandes de una columna.
goleadores %>%
filter(str_detect(Event,"G")) %>%
count(`Player Name`) %>%
arrange(desc(n)) %>%
top_n(10)
Selecting by n
# A tibble: 14 × 2
`Player Name` n
<chr> <int>
1 KLOSE 17
2 RONALDO 16
3 Gerd MUELLER 13
4 Just FONTAINE 13
5 PEL� (Edson Arantes do Nascimento) 12
6 M�LLER 11
7 Sandor KOCSIS 11
8 Grzegorz LATO 10
9 Helmut RAHN 10
10 JAIRZINHO 9
11 Karl-Heinz RUMMENIGGE 9
12 Paolo ROSSI 9
13 Uwe SEELER 9
14 VAVA 9
Al ver el resultado Juan Cruz pregunto porque si pedimos los 10 que mas goles metieron aparecen 14 resultados. La funcion top_n() va a devolver todos los casos que empaten en el puesto, asi que vemos 2 jugadores con 11 goles, 2 jugadores con 10 goles y 5 jugadores con 9 goles.
Ahora podemos usar ese resultado para realizar el grafico. Podemos extender el pipe y agregar la funcion ggplot para hacer el grafico de barras o bien podemos guardar el resultado en un objeto y luego hacer el grafico. Vamos por la segunda opcion.
Top10_gol <- goleadores %>%
filter(str_detect(Event,"G")) %>%
count(`Player Name`) %>%
arrange(desc(n)) %>%
top_n(10)
Top10_gol %>%
ggplot(aes(`Player Name`, n)) +
geom_col() +
coord_flip()
En la proxima clase veremos en mas detalle como ggplot tabaja con capas y como podemos ir cambiando los elementos del grafico y como se ven.
Ejercicio 2: Jugadores que metieron goles en el segundo tiempo.
Este ejercicio queda como tarea para la proxima clase.